Stratified and cluster sampling are two probability sampling methods that are easy to confuse — both divide a population into groups, but they do almost opposite things with those groups. This guide explains the difference, when to use each, and how to run them.
TL;DR
- Stratified sampling: divide the population into homogeneous groups (strata) by a key trait, then randomly sample from every stratum. Maximizes precision and representativeness.
- Cluster sampling: divide the population into naturally occurring groups (clusters), randomly select whole clusters, and sample everyone (or many) within them. Maximizes efficiency and lowers cost.
In one line: stratified samples a few from every group; cluster samples every (or many) from a few groups.
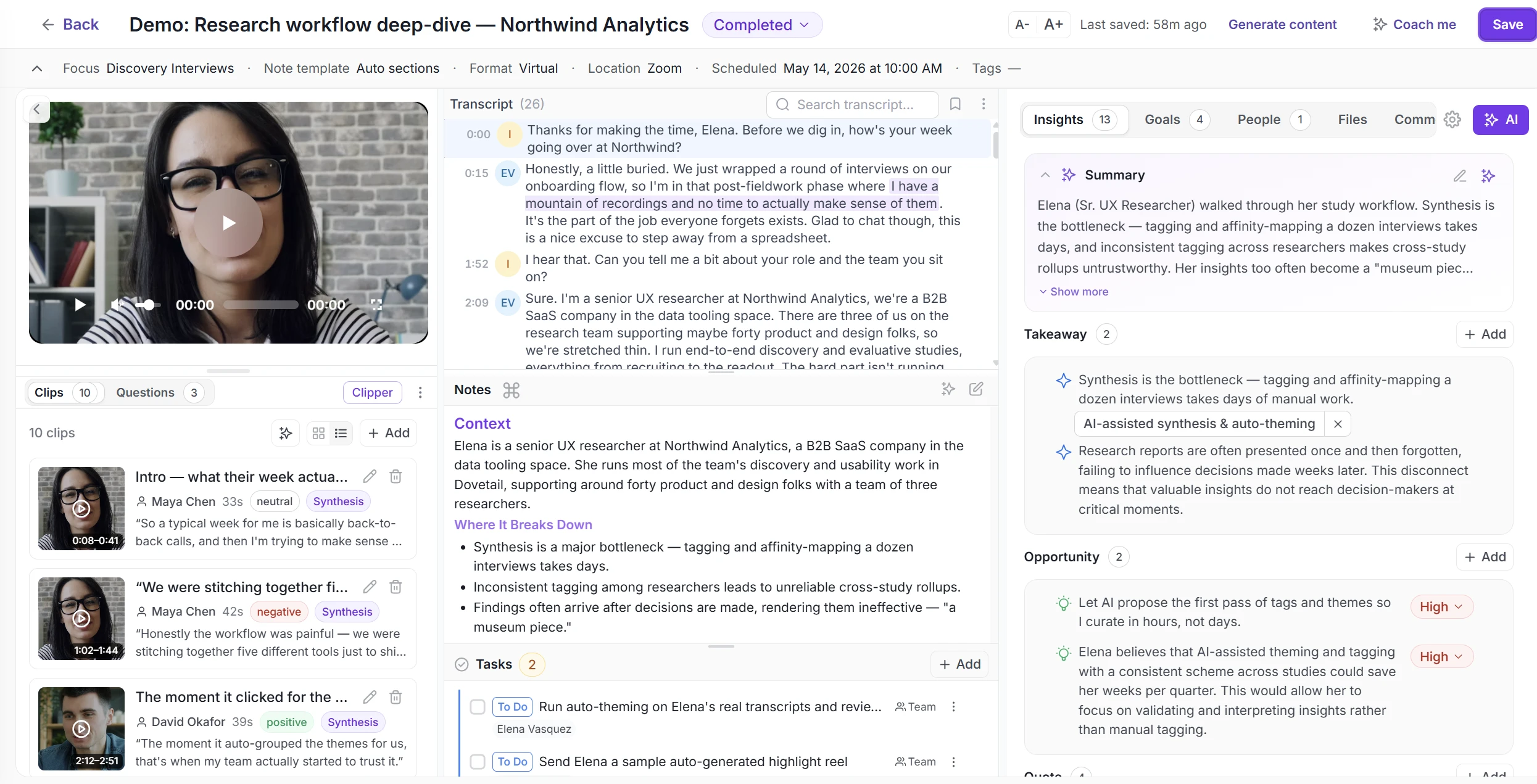
What is stratified sampling?
Stratified sampling splits your population into mutually exclusive strata based on a characteristic that matters to your study — industry, plan tier, region, role — so each stratum is internally similar. You then draw a random sample from each stratum, often proportional to its size. Because every important subgroup is represented, estimates are precise and you can compare subgroups confidently.
Example. A SaaS team studying onboarding splits users into strata by plan (Free, Pro, Enterprise) and randomly samples from each, guaranteeing Enterprise — a small but high-value group — isn't drowned out.
How to run it: (1) pick the stratifying trait, (2) divide the population into strata, (3) decide proportional vs. equal allocation, (4) randomly sample within each stratum, (5) combine.
What is cluster sampling?
Cluster sampling divides the population into clusters — naturally occurring groups like offices, schools, cities, or accounts — that are each meant to resemble the population in miniature. You randomly select whole clusters, then study everyone (one-stage) or a random sample (two-stage) inside them. It's cheaper and faster when the population is large or geographically spread.
Example. A team researching a meal-planning app randomly selects three office locations (Boston, Chicago, San Francisco) and interviews employees there — instead of recruiting individuals nationwide.
How to run it: (1) define clusters that each mirror the population, (2) randomly select clusters, (3) sample all or a random subset within each, (4) analyze.
Stratified vs. cluster sampling: side by side
| Dimension | Stratified sampling | Cluster sampling |
|---|---|---|
| Groups based on | A key trait you choose | Naturally occurring groups |
| Within-group makeup | Homogeneous (similar) | Heterogeneous (mini-population) |
| What you select | Individuals from every group | Whole groups, then people inside |
| Goal | Precision & representativeness | Efficiency & lower cost |
| Cost / effort | Higher (more planning) | Lower |
| Precision | Higher | Lower (clustering adds error) |
| Best when | Subgroups differ and must be compared | Population is large or dispersed |
Sample size and bias (the part most guides skip)
- Precision. Stratified sampling typically yields lower sampling error than simple random sampling for the same size, because it removes between-stratum variance. Cluster sampling usually yields higher error (the "design effect") because people within a cluster tend to be alike — so you often need a larger total sample to hit the same confidence.
- Sample size. Estimate size from your target margin of error and confidence level, then inflate the cluster-sampling estimate by the design effect (driven by intra-cluster correlation and cluster size).
- Bias to watch. Stratified: choosing the wrong stratifying variable, or misclassifying people. Cluster: clusters that aren't representative (selection bias), and underestimating error if you analyze clustered data as if it were simple random.
The hybrid: stratified cluster sampling
You can combine them — stratify, then cluster within strata (or cluster, then stratify). For example, stratify accounts by region, then randomly select clusters of accounts within each region. This balances representativeness with field efficiency, common in large or multi-site studies.
How this applies to customer research
In B2B and product research you rarely run textbook probability samples — but the logic still guides good customer research. Think stratified when you deliberately recruit across segments and personas so no important group is missed (and you avoid building for the loudest customer). Think cluster when you study whole accounts or teams at once.
Whatever the method, the hard part is making sense of what you hear. Intervool captures interviews across your segments and synthesizes the patterns — so a well-sampled study turns into a decision, not a pile of notes. See how it works.


